
Doing statistics can be difficult but understanding them can be fairly simple

Dear readers. the Study of the Week will need to take two weeks off. I am traveling and lecturing in Denmark.
Today I post this amazing explainer on statistics. I have read a lot on the p-value and confidence interval, and this may be the best explainer I have read. It may also be the best post we have ever had on Sensible Medicine. We are grateful to the authors and to our readers. JMM
Authors: James McCormack, BSc (Pharm), PharmD and Marc Levine PhD, Professor Emeritus, Faculty of Pharmaceutical Sciences, UBC
Most of us likely understand descriptive statistics (average, median, etc). These types of statistics describe properties of a sample.
Election results are a great example. Let’s say 10,000 people voted, and the results were 65% (6,500 votes) for party A, and 35% (3,500 votes) for party B. We might also have some demographics - average age was 47 and 55% were female etc. These are all descriptive statistics.
In an election, no inferential/deductive statistics (see below) need to be done because by definition we have counted the population of people who voted and we know the exact results. There is usually little debate about these descriptive sorts of statistics, unless of course the election was improperly run – but that has nothing to do with descriptive statistics.
Inferential Statistics
On the other hand, when we don’t study an entire population of interest, but rather a sample from that population, we need to use inferential statistics. This is where we get into all the terms you see in research papers: p-values, and confidence intervals (typically 95%) – and in the media - margin of error.
With our election example, when a poll is taken before an election, inferential statistics need to be done on the results of that poll because a poll by definition only counts as a subset of the entire population that is going to vote. Inferential statistics are done to help us use the poll results to “guesstimate” what might happen in the full election.
As an example, let’s say the results of a single poll done before the full election reported that 40% of the people polled said they would vote for a particular party. Poll results are almost always presented with a “margin of error” and that margin (for a poll size of ~1,000) is typically described as plus or minus ~3 percentage points – if so, in this case the margin of error around the 40% would be 37% to 43%.
This is where the exact interpretation of what this range means gets a bit tricky. A margin of error does NOT mean we know the true result is somewhere between 37% and 43%. In fact, we can NEVER know the true result until we have the election. What we can say is that if we were to do a similar poll 100 times, the true result (which we can’t know until we have the election) would be found between 95 (95%) of those 100 unique +/-3% ranges.
So, with this single poll, all we can say is the true result is likely somewhere between 37% and 43% but we will be wrong with that statement 5% of the time. That is literally all a margin of error tells us.
Some experts say we are 95% “confident” that the true effect is somewhere in the range of that individual poll’s margin of error, but it is not clear what that means.
What is correct to say is that, if the margin of error is correctly calculated, it is reasonable to conclude this single interval contains the true value, because 95% of such intervals derived would contain the true value. There is, however, no way to know--for certain--whether this is true for this individual poll.
Inferential statistics don’t give us a probability. Knowing this nuance is key to understanding statistics.
In a clinical trial
We also use inferential statistics when we do clinical trials, because, as with a poll, we are only studying a subset of the entire population that might possibly receive a particular intervention. So, inferential statistics are used to estimate what might happen in the entire population of subjects who could be suitable for a specific intervention.
When it comes to clinical research let’s start by understanding that the sample population selected for the trial (the poll if you will) is a subset of the potentially eligible patient population.
In an example of a drug versus placebo, the sample population is randomized into two groups. One group is given the drug, and one group is given a placebo.
When done properly randomization helps ensure (which should be the case if the sample population is large enough) a balance of potential sources of bias or confounding between the groups. There will almost always be an observed numerical difference in baseline characteristics; however, any differences are solely due to a chance effect of randomization.
The Problem of P-values in “Table 1”
Until recently, it was common to see baseline characteristics be subjected to inferential statistics and each baseline characteristic in the table would have an associated “p-value.” This shows a complete misunderstanding of the purpose of inferential statistics.
In the assessment of a clinical trial, we want to know if differences in baseline characteristics may have played a role in the observed outcome. To do that we simply need to know exactly what the differences in baseline characteristics ended up being. Because we have baseline characteristics for everyone in the study sample, all we need is simple descriptive statistics and then look for any differences.
The issue is not…if the differences are statistically significant. The question to consider is…are the actual differences seen between the groups with regards to baseline characteristics large enough to have influenced the outcome? That is a question answered by looking at descriptive statistics and using clinical judgement, not by incorrectly doing inferential statistics.
There are trials in which sensitivity analyses can be done to determine whether certain characteristics could have influenced the outcome but that is a much different statistical evaluation.
We present the p-value-in-Table-1 mistake as an important example of just because you can do inferential statistics on a set of data doesn’t mean it has value.
Back to the Trial
With proper randomization, the two groups should be well balanced with regard to baseline characteristics and therefore have no notable sources of bias and confounding. If this is the case then there can be only three possible explanations for the observed difference between the groups.
1. There is an undetected source of bias or confounding
2. The result really was due to chance
3. If we do not believe chance is the explanation or that there is a substantial source of bias or confounding, then the only conclusion is that the intervention really did cause the outcome
Another example: let’s say this trial was of a new medication thought to possibly reduce the chance of a person having a heart attack. One group will get the medication and one group will get placebo. The null hypothesis, which is part of the statistical hypothesis, is that the new medication has no effect and that we should therefore see very similar chances of heart attacks in both groups. This is the null hypothesis (no effect).
Inferential statistics actually do NOT help us test a research hypothesis about whether an intervention worked or not. They assume the observed difference was solely due to chance and simply give us an estimate of the probability of such an occurrence over many potential repetitions of the study.
In this case, one group gets the new medication, and the other group gets placebo, and the authors count up the number of people in each group that have a heart attack after say 5 years.
The numbers of heart attacks in each group will likely be numerically different, so then we must make a decision: do we think the numerical difference seen was due to chance or not? We actually have no way of knowing or determining this, therefore, the p value arose simply as a criterion to help us reduce subjectivity in making this decision.
As noted above, we consider the three possibilities (confounding due to bias, chance, or real effect).
Inferential statistics simply deal with the second point – chance – nothing else.
No statistics can tell us if the medication worked or if the differences seen were clinically important. These decisions are clinical judgments--not statistical judgements. The ONLY reason we do inferential statistics is to singularly deal with the issue of chance. This concept is key to understanding inferential statistics.
When trial results are presented, we need not worry too much about the complex mathematical computations underlying the statistical presentations. As users of medical evidence, we very much need to know how to interpret the way the results are presented and what they do and do not mean.
Similar to our margin of error polling example, when it comes to clinical trials. if we calculate a 95% confidence interval for the observed difference between the groups, then 95% of all the confidence intervals we observe from multiple trials would contain the true value.
The Origin of the 95% Confidence Interval
Let’s first understand why we use a 95% confidence interval versus some other range.
Roughly 100 years ago the statistician Ronald Fisher somewhat arbitrarily proposed that exceeding a p-value of <0.05 (<1 in 20 - which is akin to a 95% confidence interval) should be the threshold for statistical significance. This threshold has been debated often since its introduction, but it has stood the test of time, at least in medicine.
P-values do not tell us if a treatment worked. There is also a problem with holding any specific “threshold” p-value as sacrosanct. A p-value should not be considered a black-and-white dichotomous criterion for whether a result should be considered statistically different or not (ie. whether they believe the observed difference was due to chance or not).
A p-value should not be used to infer a particular treatment “worked” if this threshold was reached. There are no meaningful differences in the interpretation of findings with say a p-value of 0.06, 0.05, or 0.04.
The desire of investigators to show their difference observed is “real” has led many researchers to go to elaborate machinations to ensure their findings reach the penultimate p-value threshold. We have seen researchers report the p-value to many decimal spaces (e.g., 0.0498) to make sure they could say their results are statistically significant (<0.05).
All statistics can do is tell us is… if there was no effect of the treatment, how often would we see a result like the one seen, or more extreme, simply by chance.
Subtleties of confidence intervals. As with poll results and margins of errors, each finding of a clinical trial can be presented as a point estimate. This is the outcome difference observed – along with a p-value and hopefully in most cases a more informative confidence interval. In fact, if a confidence interval is provided, a p-value adds very to the interpretation of the findings.
A couple of real-life examples
A) The main outcome from the 2000 HOPE trial (ramipril versus placebo in higher cardiovascular risk patients) was the risk of heart attacks/strokes (CVD) over 5 years.
A CVD event occurred in 17.8% of the placebo group and 14% in the ramipril group. The point estimate for this outcome was reported as a relative risk of 0.78, a p-value of <0.001 and a 95% confidence interval of 0.70 to 0.86 in favour of ramipril.
How should this result be interpreted?
Even without a p-value, we know the result would be considered statistically significant because the confidence interval does not include a risk ratio estimate of 1.0, which in trials with dichotomous (heart attack yes or no) outcomes indicates no difference (e.g., if the risk of heart attacks/strokes in each group was the same, say, 10%, then the risk ratio, 10%/10% = 1.
In the trial, the risk of CVD was 22% lower in the placebo group (0.78 is 22% less than 1.0) – so roughly an ~1/4 reduction in the risk of a CVD event.
The p-value suggests the chance of seeing a difference this large or even larger if the drug had no effect and there was no bias or confounding, would be <0.1% (0.001 = 0.1%).
A reasonable way to interpret a single confidence interval from a single trial is to say the relative benefit is likely somewhere between 30% (0.70) and 14% (0.86). But. You can’t put a probability on this because inferential statistics are not determinants of probability.
As a clinician, if both a 30% and a 14% relative difference (the edges of the confidence interval) would be considered a clinically important difference, then one could conclude this trial shows the drug ‘works’ and that the magnitude of the effect is clinically important—in these types of patients and in this sort of trial setting.
One also needs to know the baseline risk in the placebo group. In Hope, the 5-year CVD risk in the placebo group was ~18%, so the absolute benefit is roughly 1/4 off of 18% which is ~4%. In other words, for the average effect, m4% of people benefitted and 96% did not, but the absolute effect could be as big as ~5.5% or as small as ~2.5%, if one uses the relative numbers from the edges of the confidence interval.
That’s it. There really is nothing more statistics can tell you. Obviously, there is much more to using and appraising evidence such as looking for biases, clinical judgement, patient values and preferences, but “the chance” is all inferential statistics can tell you.
B) Another example comes from an article I co-authored in 2013 entitled “How confidence intervals become confusion intervals"
One example we gave was showing the point estimates and confidence intervals from 5 different meta-analyses that evaluated the impact of statins on mortality in primary care.
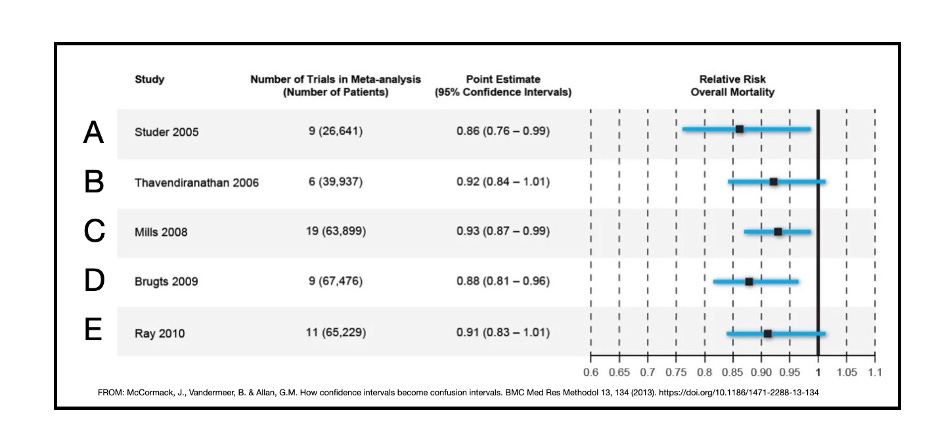
The authors of the B and E meta-analyses concluded there was no effect of statins on mortality (because their confidence intervals included 1.0) whereas the authors of A, C and D concluded that statins reduced mortality (because their confidence intervals did not include 1.0). Their interpretations of their findings are incorrect.
Here is what we said about this in our paper.
“Although the different meta-analyses included some different studies, overall, the investigators used similar data and, not surprisingly, found similar results. The range of point estimates was 0.86 to 0.93 with an average point estimate of ~0.90. The lower limits of the CIs ranged from 0.76 to 0.83 and the upper limits ranged from 0.96-1.01.
The CIs overlap considerably and there is little meaningful difference in the results. The only ‘differences’ lie in three meta-analyses in which the upper limits of the CI fell just below 1.0 and just above 1.0 in the other two. It appears the differing conclusions were due solely to a proclivity for a p-value of 0.05 and adherence to statistical significance as a dichotomous outcome.”
Another way to consider these results is that, if you were a betting person, you would say statins likely reduce mortality in this population. If one had to estimate the effect size, ~10% relative reduction is not an unreasonable number to use but the confidence intervals suggest the effect size could be as large as ~20% or close to a zero effect. That’s it.
One shouldn’t say there is a ‘trend” towards a mortality benefit. There is no such thing as a statistical trend. As Nead et al state
“There is no definition of a trend toward statistical significance and, therefore, describing ’almost significant’ results as a trend introduces substantial subjectivity and the opportunity for biased reporting language that could mislead a reader.”
Additional notes on confidence intervals
The width of the confidence interval depends to a large extent on how many people were in the experiment as well as the event rate
The more people we study the tighter/smaller the confidence interval becomes. Why: the more people we study the closer we are getting to studying the entire population and once we study everyone, the confidence interval becomes zero--because we now know the result.
Looking at the sample size and endpoint of a trial can sometimes be informative as it hints at the anticipated magnitude of the benefit/harm of a particular treatment.
Large trials (say 1000+ people) are done primarily for 1 reason: the anticipated absolute benefit or harm of a treatment is thought to be <5-10% (sometimes as little as 0.5-2%) over 1-5 years, and to rule out chance you must enroll 1000s of people. Examples of trials of medications that have/will require 1000s of people to identify a statistically significant difference in important clinical outcomes (if one exists) include risk reduction trials of lipid/blood pressure/glucose medications and COPD trials comparing triple therapy inhalers to dual therapy.
For context, consider how few people you need in a trial when you have a treatment that works in almost everyone.
For something like general anesthesia, you really don’t need to do, and shouldn’t likely do, a placebo-controlled trial to prove efficacy. General anesthesia puts almost everybody to sleep and allows major surgery to be done relatively pain free. On the other hand, virtually no one simply falls into a deep sleep enough to allow us to do surgery. General anesthesia is an example of the “All or None” level of evidence which is rated as level 1 evidence (the highest level of evidence along with well-designed RCTs).
If one was to do a placebo-controlled trial of general anesthesia, all we would need is 4 subjects in each group to show a statistically significant result. In the anesthesia group, all 4 would fall into a deep sleep and surgery could be completed – in the 4 that got placebo, surgery would be terribly unpleasant.
If you do inferential statistics on these results 4/4 (100%) for general anesthesia and 0/4 (0%) you get a p value of ~0.03 which is below the often used 0.05 threshold. In other words, we would, by convention, rule out the findings were simply due to chance.

Key summary points about inferential statistics
The sole purpose of inferential statistics is to answer the single question: if there was no effect of a treatment and there was no substantial source of bias or confounding, how often would we see the result found, or a more extreme result, by chance alone if the study were to be done many times. (Editor’s note: I consider the p-value a surprise value.)
A statistically significant difference does not mean a medication or treatment worked or did not work; you have to look at the rest of the body of science around the issue. If one decides that chance is not the explanation and is confident the study was not biased or confounded, then it can be inferred that the intervention had an effect. This should always be interpreted in the context of what previous literature shows about the intervention, the apparent effect, the clinical importance of the effect size and the risks of the intervention to the patient.
A threshold for statistical significance should never be thought of as a dichotomous finding.
A confidence interval is simply a range of values within which we think the true value of the difference lies, but we understand that on average, 5% of all the confidence intervals we determine this way will actually not include the true value. There will always be a degree of uncertainty that cannot be overcome.
The narrower the confidence interval, the higher the precision of the estimate
If the benefit being described is a relative number, it is important to look closely at the data to gain an understanding of the baseline risk of the outcome in placebo treated patients as this lead us to the absolute difference.
 | A guest post by
|
There is much, much good in this article. The authors started out with great pains to interpret a confidence interval exactly correctly. Then they made a mistake:
"So, with this single poll, all we can say is the true result is likely somewhere between 37%
and 43% but we will be wrong with that statement 5% of the time."
No. Both parts of this sentence are incorrect. In frequentist statistics the true value is either in or outside the interval; there is no probability attached to this. The probability statement does not apply to 0.37 and 0.43 but to the process that generated this interval.
The extreme difficulty in interpreting confidence intervals should drive more people to Bayes, as described in my Bayesian journey at https://fharrell.com/post/journey.
Later the authors say
"Inferential statistics actually do NOT help us test a research hypothesis about whether an intervention worked or not. They assume the observed difference was solely due to chance and simply give us an estimate of the probability of such an occurrence over many potential repetitions of the study."
This is incorrect, as the statement applies only to classical frequentist inferential statistics. Any article on statistics that doesn't acknowledge the existence of Bayes is problematic.
Now take a look at
"No statistics can tell us if the medication worked or if the differences seen were clinically important. These decisions are clinical judgments--not statistical judgements. The ONLY reason we do inferential statistics is to singularly deal with the issue of chance. This concept is key to understanding inferential statistics."
That is false as again it applies only to classical frequentist statistics. With Bayesian posterior probabilities you are not needing to deal with "chance" in the sense above, and you obtain direct evidence measures such as the probability the treatment has any effectiveness and the probability of clinically meaningful effectiveness. And Bayesian uncertainty intervals are so much easier to interpret than confidence intervals.
An article about statistics should be exactly correct to not mislead readers, and researchers should stop pretending that the p-value/confidence limit form of interence is the only form that exists. Otherwise, new confusions will arise.
Thank you! Regression analysis aged me. Wish I came across this summary last year - it’s a solid overview of concepts that appeals to all students wherever they are on the learning continuum. Statistics is a blood sport not for the faint of heart nor online orphans.