
Nutrition Churnalism Part 2


If you haven’t already read last week’s post on nutritional churnalism, please do as we are going to build on it here.
Before laying our nutritional churnalism background to rest, let us move from misleading news coverage to a research study that demonstrates why a lot of nutritional research is flawed. As we mentioned last week in the introduction, it is unfair to pile too much blame on the journalists when so much of what makes churnalism possible is shoddy research.
Because we know that exposure to certain things -- cigarette smoke, ionizing radiation, some industrial chemicals -- play a role in the development of cancer, it is tempting to assume that individual, raw ingredients, ingested as part of a regular diet, also might affect our risk of developing cancer. For the vast majority of ingredients, however, there is no reliable evidence that any one ingredient increases or decreases an individual’s risk of cancer in a clinically or statistically significant way. Nonetheless, studies that link particular nutrients to greater or lesser cancer risk are remarkably common.
A few years ago, researchers did something very provocative. Joshua Schoenfeld and John Ioannidis opened The Boston Cooking-School Cook Book and randomly picked ingredients. For each of the ingredients, they searched the biomedical literature to discover how many had been linked to cancer.
The researchers found that 40 of the 50 ingredients had at least one paper testing whether it was linked to cancer. And for 20 of the ingredients, there were more than 10 studies. About a quarter of studies found no link between the ingredient and cancer, but the rest demonstrated that the ingredients either increased or decreased risk.
One figure from this paper, reproduced below. This figure shows the results particularly well. For the 20 ingredients that had been examined in at least 10 studies, the estimate of cancer risk was all over the place. For 17 ingredients, there were studies that claimed both that the ingredient was cancer fighting and cancer causing. Only three of the ingredients had consistent findings: bacon and pork, bad; olives, good.

There is one more really important figure from this paper. Before we get to it, though, we need to discuss some statistics. Wait, don’t stop reading. We are going to stay away from any really mind-numbing discussions of statistics but for this figure we need to remind you of some basics. Medical studies often examine how people respond to an exposure. Studies are actual experiments, in which researchers give one group of people a medication and another group a placebo and watch to see if one group does better than the other. Other studies are observational, the kind that we have been discussing. In these studies people decide if they are going to, say, eat a vegetarian diet or not, and the researchers just watch to see which group ends up happier and healthier. Such a study might show you that 5% of the vegetarians died over 20 years while 8% of the omnivores died. No statistics are needed to understand these results. More omnivores died than herbivores. We do need statistics to understand if this is an important result, one that can be extrapolated to other, similar populations. The finding might be a real robust result that can be expected to be present in larger groups, or the result might just be noise, the random variation that is observed in small samples. If you flip a coin ten times you might get 8 heads instead of the expected 5. This is just noise. We use statistics to help us differentiate signal from noise.
Let’s get back to the Schoenfeld/Ioannidis paper. This next figure, taken from that article, graphs transformed Z-scores against the number of studies.
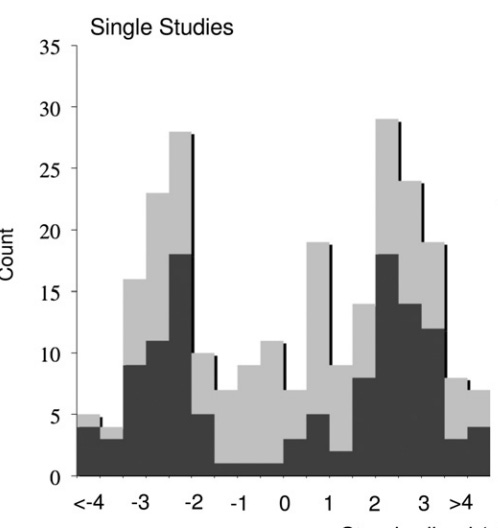
A result is considered statistically significant when the Z-score gets close to -2 or +2. What is striking about this graph is that there are 2 spikes, both just beyond the cutoff points for statistical significance.
What does this mean? If common sense dictates that an increase by one serving of a common ingredient does not confer detectible, statistically significant, differences in cancer rates, then how can it be that 80% of ingredients have been linked to cancer in a published study (often showing both protective and carcinogenic effects)?
The explanation, demonstrated well in the figure, is that the results are often barely statistically significant—in either direction. The results are noise rather than signal. They are findings that may be present in a small sample of people in one study, but are meaningless to you. Researchers across the globe are probing relationships. Most of the results they are getting are negative, they find no relationship between exposure X and outcome Y. One ingredient, one more time per week, whether it is lentils, or inulin, or kale, has nothing to do with cancer. But there are many cancers to test for, and many variables to adjust for, and by chance alone some analyses find a relationship that “reaches statistical significance.” These random, fluke findings are precious little gems. With a few cuts, and some polish, they can be written and published in medical journals. Some even make the daily news.
That is what is going on here. There is a lot of research randomly generating results, and results that are sexy, and seem plausible, get amplified. Results that are boring and dull get buried. Either no one writes them up or they are rejected by journals as uninteresting negative studies. The formal terms for this course of events are selective reporting bias and publications bias, respectively. It is the result of researchers and editors being picky about what they report and accept that the published literature is not the truth, but the tip of the plausible iceberg.
Ioannidis put it this way in another article, “When the number of potential studies that have not existed is large, then the published literature is mostly a reflection of what is considered plausible and reasonable by experts in the field. Thousands of scientists could have data-peeked; their decision to generate and publish a full study with specific results is molded by their expectations and the expectations of peers… Accordingly, some observational evidence about commonly and easily measured exposures and outcomes resembles an opinion poll or self-fulfilling prophecy...”
We consider this the 6th deadly sin of churnalism: keep testing, report just once. We will try to keep providing more evidence to convince you that this synthesis is correct, that many researchers are testing certain hot topics over and over, that their analytical plans are flexible, and as such they generate a broad range of results. Only some of these results -- the ones that are provocative, acceptable, and the ones that reach (or can be made to reach) “statistical significance” -- filter through the journals and into the news stream.
Over the last 70+ years of my life, food fads have come and gone. Studies have made claims that certain foods are bad or good for you, only to decide that it wasn’t bad or good after all. Eggs, butter, margarine, meats... are just a few. Why was the question. With enough research money and motive you can prove or disprove most studies. Critical thinking is seriously needed to navigate the maze.
....which is why we need more journals like the Journal of Articles in Support of the Null Hypothesis.
Pre-registration of studies also helps.