
Randomize NIH grant giving

A pause in NIH study sections has been met with fear and anxiety from researchers. At many universities, including mine, professors live on soft money. No grants? If you are assistant professor, you can be asked to pack your desk. If you are a full professor, the university slowly cuts your pay until you see yourself out. Everyone talks about you afterwards, calling you a failed researcher. They laugh, a little too long, and then blink back tears as they wonder if they are next. Of course, your salary doubles in the new job and you are happier, but you are still bitter and gossiped about.
In order to apply for NIH grants, you have to write a lot of bullshit. You write specific aims and methods, collect bios from faculty and more. There is a section where you talk about how great your department and team is— this is the pinnacle of the proverbial expression, ‘to polish a turd.’ You invite people to work on your grant if they have a lot of papers or grants or both, and they agree to be on your grant even though they don't want to talk to you ever again.
You submit your grant and they hire someone to handle your section. They find three people to review it. Ideally, they pick people who have no idea what you are doing or why it is important, and are not as successful as you, so they can hate read your proposal. If, despite that, they give you a good score, you might be discussed at study section.
The study section assembles scientists to discuss your grant. As kids who were picked last in kindergarten basketball, they focus on the minutiae. They love to nitpick small things. If someone on study section doesn't like you, they can tank you. In contrast, if someone loves you, they can't really single handedly fund you.
You might wonder if study section leaders are the best scientists. Rest assured. They aren't. They are typically mid career, mediocre scientists. (This is not just a joke, data support this claim see www.drvinayprasad.com). They rarely have written extremely influential papers.
Finally, your proposal gets a percentile score. Here is the chance of funding by percentile. You might get a chance to revise your grant if you just fall short.

You might wonder if better percentile scores mean more productive grants. Here are two ways to look at it:

And now the ROC curve
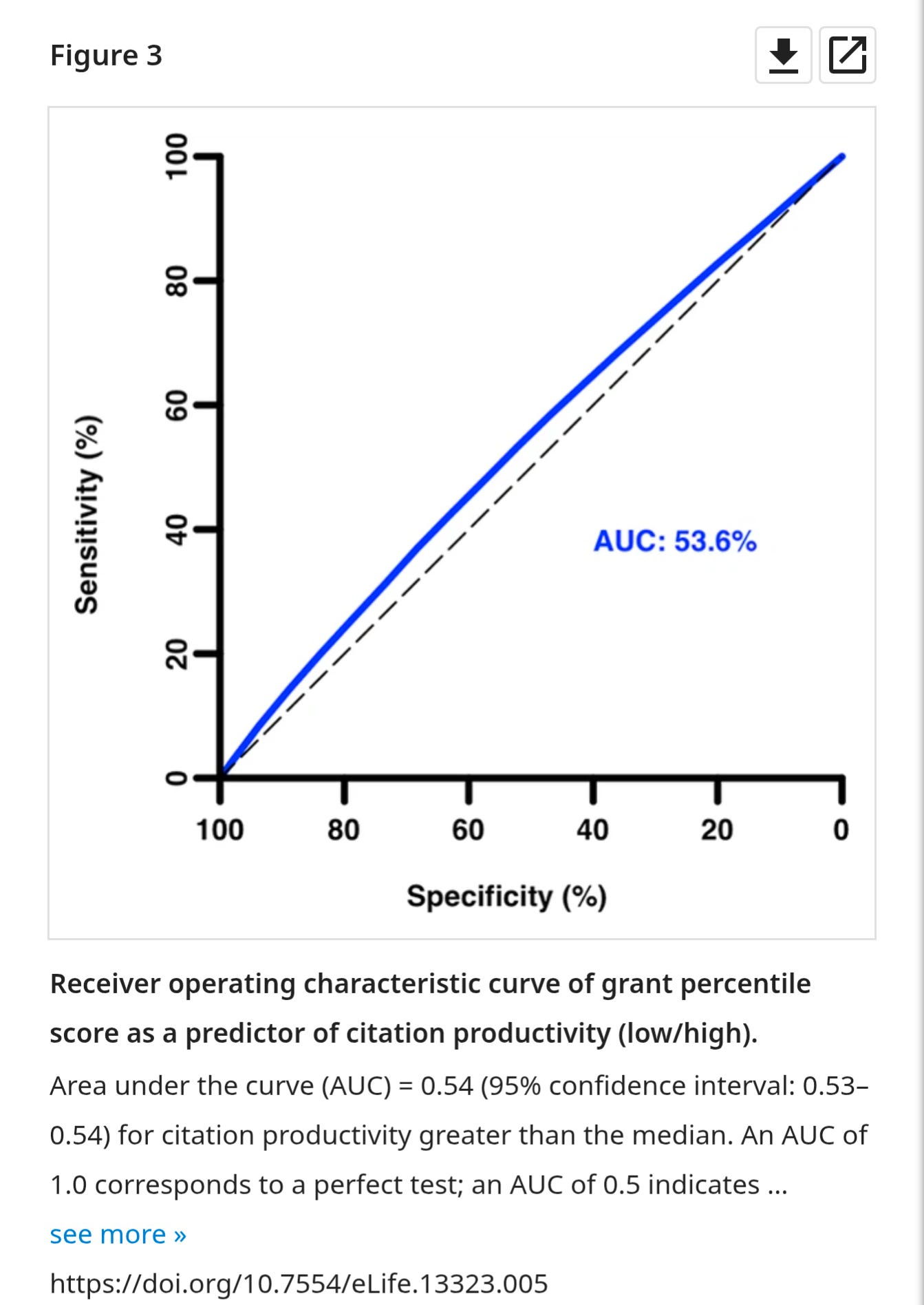
It appears the study section is as good as a coin flip. Aka. Percentile of 1 is little different than 4 or 11 It's nearly entirely arbitrary. We don't know if percentile 60 is as good bc we don't have enough data. Of course, I'll be the first to concede that the evidence I'm using also has severe limitations, because high percentile grants are not funded at random. But all of this just supports the need for a randomized study.
Given that the current system is onerous and likely flawed, you would imagine that NIH leadership has repeatedly tested whether the current method is superior than say a modified lottery, aka having an initial screen and then randomly giving out the money.
Of course not. Self important people giving out someone else's money rarely study their own processes. If study sections are no better than lottery, that would mean a lot of NIH study section officers would no longer need to work hard from home half the day, freeing up money for one more grant.
Let's say we take $200 million and randomize it. Half of it is allocated to being given out in the traditional method, and the other half is allocated to a modified lottery. If an application is from a US University and passes a minimum screen, it is enrolled in the lottery.
Then we follow these two arms into the future. We measure publications, citations, h index, the average impact factor of journals in which the papers are published, and more. We even take a subset of the projects and blind reviewers to score the output. Can they tell which came from study section?
I know that these metrics are imperfect. But they are still telling. What if we fail to find any differences? Or what if, the modified lottery actually does better? One immediately implication of that would be that we don't need to write 30-page grants. We can write a one-page grant. Immediately, millions of hours of research time will be freed up.
There are many other arms we can try. We can have an initial screen and ask reviewers to pick winners solely based on past output. Fund people not projects. What if we randomly pick some of your work and try to replicate it and fund you based on replication rate. Or instead of reviewing your science proposal, we can judge you based on how well you review a science paper. One can imagine many things can be tested. I personally favor modified lottery as a first study. I would randomize all of these things however.
If the federal government were a corporation, they would absolutely do this. You could not justify giving money year over year without knowing if you are efficiently doing it. But, sadly leadership at NIH has never done this. A few years ago, Francis Collins had a proposal to limit the number of r01s to three, but even this was met with tears, particularly from researchers benefiting from the current system. Collins, in typical fashion, backed away from any leadership.
That's the funny part about this whole mess. Even though the system is deeply sub-optimal, and even though everyone hates it, reform is still challenging because scientists will cry, “you are killing people” and “what about the cures!”. Already this month we've seen these cries.
I've seen scientists say I was counting on the study section. How could you count on them? The percentile ranks are very capricious. You should always have a backup plan. I've seen scientists say that money is being delayed. But this is dishonest. No study section meets on Monday and gives out money on Tuesday. There's a minimum of 4 to 6 months, for the government to do anything.
As is off in the case in science and medicine, the biggest barrier to improvement, is that some people are content in the current system. But this isn't a good reason. We owe it to the public to study formally. Whether or not the method we use to give out grants is optimal. And if we don't do it, not only should they put a pause on our grants for one month, they should suspend them indefinitely. Because we have failed to uphold our bargain in the social contract.
Instead, I would rather see us conduct studies, repeatedly, to learn of our processes are efficient. I would like to see us incentivize reproducibility. And then, if we are able to deliver, I would like to see the percent of funding going to science increase. I believe that in a working society, 10% of health care spending should be on medical research. But in a broken system, it's hard to justify even a fraction of this.
Considering that this is Sensible Medicine, I’ve been a bit surprised by the lack of balance with respect to the discussion of NIH funding mechanisms. In many ways they read as if grievances are being aired against study section reviewers who didn’t happen to like your grants.
As NIH funding is relatively mysterious to those who don’t apply for federal grants, phrases such as “Ideally, they pick people who have no idea what you are doing or why it is important, and are not as successful as you, so they can hate read your proposal.” might be assumed to be semi-serious by a casual reader. The goal, of course, is to have experts read your grants on NIH study sections, but this is achieved with various degrees of success.
Yes, NIH study sections and funding mechanisms are mercurial and inefficient. Yes, the expertise of the panels could always be improved. Yes, a randomized assessment of funding approaches is a good idea. But we need to be careful about what we consider to be a successful or impactful grant, and there are a couple of assertions here that are fairly easy to take issue with. For example, the idea that you are “mediocre” as a scientist unless you have a paper with at least 1,000 citations is complete nonsense. This number is entirely arbitrary and does not translate over all (most?) areas of research. In fact, if you want more innovative thinking in the NIH, stacking study sections with establishment scientists who have hung around long enough, and learned to play the game well enough, to have lots of papers with over 1,000 citations might be exactly the opposite of what’s needed.
I work in neonatal neuroprotection, developing therapies for babies with various kinds of brain injury. The number of serious labs doing preclinical (animal) work to support and inform future clinical trials can be counted in the 10s worldwide. Despite this, the field developed what I would argue is the most recent major therapeutic advancement in neurology – therapeutic hypothermia (TH) for newborn infants with hypoxic-ischemic encephalopathy (HIE). TH for HIE was added to resuscitation guidelines in 2010 and is incredibly effective – the NNT to prevent death or major disability is 7. The study in piglets that established the mechanism has been cited 495 times according to Google Scholar (Thoresen et al., Pediatric Research 1995). The study in sheep that developed the TH protocol now used clinically (Gunn et al., JCI 1997) has been cited 732 times. These papers formed the basis of a therapy that will save millions of lives, but there simply aren’t enough people in the field for them to hit an arbitrary number of 1,000 citations so that they can suddenly be considered impactful work by “good” scientists.
Suggesting that a grant is only successful if it results in a large number of citations or publications is equally problematic. I could highlight evidence that scientists who have more papers, more citations, and publish in higher impact journals are, on average, more likely to have their work retracted and therefore suggest that they are “worse” scientists. Of course, we know this isn’t true.
The NIH could absolutely use some reform, but sticking with these outdated metrics of “success” as the goal will only decrease the quality of the output as people try to crank out more papers and get more citations. Instead, there should be field-specific assessments of success, for instance translation of therapies from preclinical to clinical trials and, ideally, successful clinical trials that have meaningful outcome metrics.
A very long exposition. You have become an apologist for this renegade anti-science administration. They will take you all down. Buyer beware