
The “evidence pyramid” should be dismantled, brick by ill-conceived brick
Sensible Medicine is pleased to offer this guest post from Dr. Michael Putman, who argues against the entire notion of an evidence pyramid

I wrote last week about a systematic review of physical measures to block viral transmission. In the post I referenced the famous (or perhaps infamous) evidence pyramid. My goal was to show the idealized version of evidence—wherein a systematic review of randomized trials strengthens one’s confidence in any one trial’s signal.
This week, Dr. Michael Putman, an Assistant Professor of Medicine at the Medical College of Wisconsin, writes a compelling rebuttal of the entire concept of the evidence pyramid. We are pleased to publish this well-written argument, even though I disagree with parts of it. Indeed, that is the point here at Sensible Medicine. JMM
By Michael Putman
People love pyramids. The Egyptian ones have existed for nearly as long as humans have understood geometry, and their graphical descendants have been used to explain everything from nutrition to self-actualization.
Pyramids appeal to our innate appreciation for proportion and symmetry, conveying a sense of stability that has graced beautiful museums and inspired countless childhood sand castles. They have also lent credence to the most aggravating and misleading evidence-based medicine meme in existence – the so-called “evidence pyramid.”
The evidence pyramid has gone through many iterations over the past 20 years, but a representative example is pictured below.
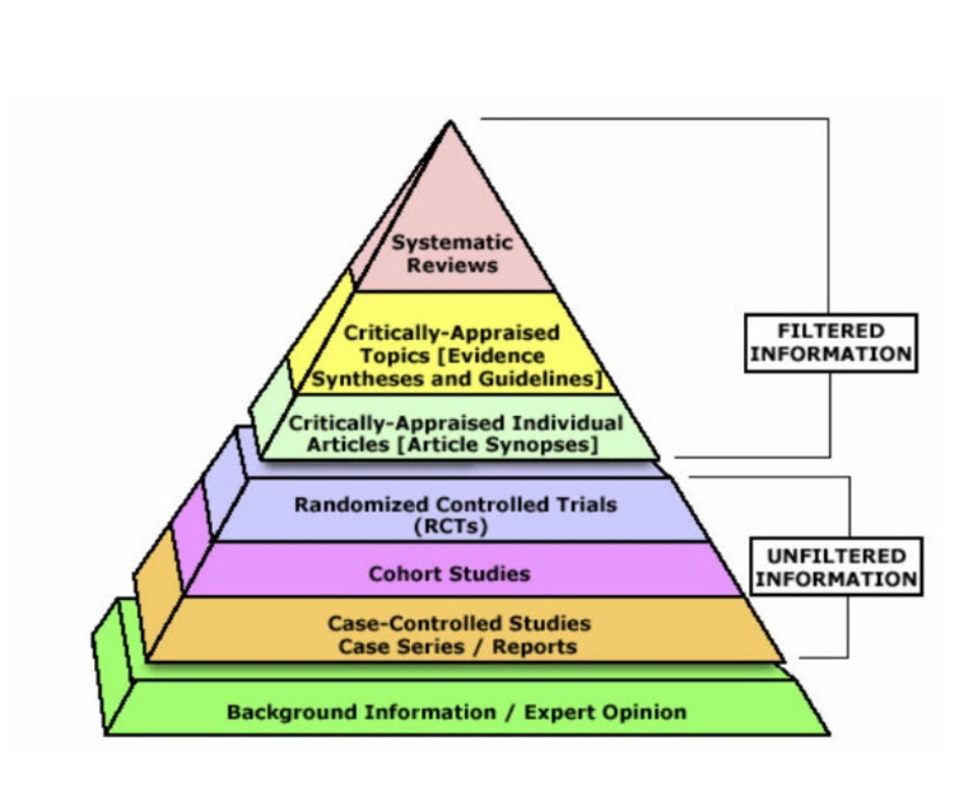
At the bottom of the pyramid, we have case reports and expert opinion. Observational data of some variety typically holds the next rung up, followed by randomized controlled trials (RCTs) and then – at the very pinnacle of “evidence” – the systematic review +/- meta-analysis (SRMA). This not only looks pretty and seems reasonable, but it offers an accessible hierarchical framework for understanding what “evidence” you can trust.
None of us actually believe this.
When was the last time you resolved an obscure clinical question by digging through case reports? You probably texted a colleague for an expert opinion, because you know their experience holds greater weight and is stronger “evidence” than an anecdotal report in an open access journal that nobody reads.
When was the last time the FDA approved a novel drug because it demonstrated superiority in a “pivotal systematic review?” That would be nonsensical, because our regulatory agencies (correctly) require experimental evidence and (correctly) interprets the evidence themselves. Even a cursory review suggests that this hierarchy is just wrong.
First and foremost, systematic reviews and meta analyses (SRMAs) are emphatically not the highest level of evidence. I would argue they are not themselves evidence at all, but rather a lens through which we view actual evidence from RCTs and observational studies. They depend upon the quality of the review process (many are very low quality) and the evidence that they appraise (often small studies with various methodologies). Moreover, because there is a “mass production of redundant, misleading, and conflicted systematic review and meta-analyses,” the chances that a given meta-analysis represents a true finding is likely less than 50%. In fact, under current assumptions a famous paper by J.P. Ioannidis (over 10,000 citations since 2005!) suggests this to be case.
The gold standard of medical evidence – the randomized controlled trial – should be at the top of any “evidence pyramid.”
We should, however, also acknowledge that many RCTs are poorly conducted, underpowered, and susceptible to bias from the pharmaceutical industry that (generally) runs them.
We know this to be the case, as over half of phase 3 trials fail (despite having encouraging preclinical and phase 2 trial data to support them) and medical reversals are common (even among practices that had support from an RCT).
Instead of sharp lines separating randomized data from observational data, we should recognize that some trials are worse than some cohort studies, and balance them accordingly.
I would love to take credit for this framework, but these concerns have been noted before, and these very revisions have already been proposed by Hassan Murad, an epidemiologist who runs the Mayo Clinic Evidence-Based Practice Research Program.
In a 2016 BMJ perspective that has been cited nearly 1,000 times, he suggested the following: (1) remove SRMAs from the top of the pyramid, revealing RCTs to be the highest level of evidence, (2) make the lines between study types wavy to reflect intra and inter study-type variations in quality, and (3) re-conceptualize SRMAs as a “lens through which evidence is viewed.” If you simply must share a pyramid, I highly suggest that you chose this one:

But must we share one? The goal of critical appraisal should be to assess an individual study, not a study type.
In the past year I have read multiple important randomized controlled trials that immediately changed my practice, but I have also read regrettable ones that used meaningless primary outcome measures, subjected patients to inadequate background standards of care, or had their conclusions misconstrued by an industry funded medical writer.
I have read dozens of provocative and well-conducted observational studies, but I have also suffered through worthless fishing expeditions and studies that seemed expertly designed to measure nothing more than confounding. At no point would an evidence pyramid have improved my interpretation of their data or positively affected my ability to describe them.
In summary, do not share the evidence pyramid.
If you must share one, choose one that places RCTs at the top and relegates SRMAs to the role of a lens by which actual evidence is interpreted.
Remember that good observational studies may be better than bad RCTs. And most of all, read and judge each paper by its individual merits not by its strata on a colorful triangle.
Mike Putman is an Assistant Professor of Medicine at the Medical College of Wisconsin, where he is the Medical Director of the Vasculitis Program and maintains an active practice in general rheumatology. He is involved in education and currently serves as the Associate Program Director for Rheumatology and Associate Program Director for Internal Medicine. His research interests include clinical trials in vasculitis, “big data” epidemiology, and meta-research. He is also an Associate Editor of the journal Rheumatology and hosts the Evidence Based Rheumatology podcast. You can follow Mike on Twitter @EBRheum
 | A guest post by
|
Here's another obvious point, but still worth mentioning: selection/publication bias shapes a narrative that promotes the vested interest, but deviates from reality. E.g. A drug company funds two studies: one shows benefit, one doesn't. Guess which one the company's researchers submit for publication. Same holds for journal editors.
The CDC cherry picks studies -- most using dismal methodology -- that support a narrative such as the putative benefits of mask wearing to prevent covid or the supposed benefits of Paxlovid. Very, very often industry-sponsored studies use statistical tricks to hide the untoward effects of a drug or device to create an illusion that the risk/benefit of their drug/device is favorable. Or they simply ignore untoward effects altogether.
The examples of flawed studies and manipulated data are too numerous to count. A prudent medical professional should retain extreme skepticism.
this is a strong take and one with which i very much agree.
"lying with meta studies" has become something of an art form and the selective assembly of poor and mediocre data gets used to swamp the good data.
it's the equivalent of badly balancing cohorts in CT and them trying to back out bias at the end with some sort of cox model.
your study is not longer a study. it's not only as good as its modeling parameters.
what you want is the best overall study done sufficiently soundly that adjustment is not needed.
that and only that is data.
the rest is estimation and skullduggery.
been seeing A LOT of this in epidemiology. they seem to use statistical tool predominantly to occulde and not to reveal.
feels like a badly broken field.