
Using Instrumental Variable (IV) methods to estimate the effect size in Colonoscopy Screening Trial (NordICC)

It is my pleasure to welcome this guest post by Prof Recht at Berkeley, CA. We have covered the NordICC trial of colonoscopy extensively— because it is big news, and because it matters. I recently interviewed the PI for Plenary Session (check it out on your podcast app). Here, we analyze it with instrumental variable methods. What the hell does that mean?
One limitation of the per-protocol analysis is that it can have residual confounding. The 42% compliant with colonoscopy are different than the 58% who aren’t in ways we can measure (and adjust for) and ways we cannot.
The IV method adjusts the intention to treat effects for imperfect compliance, scaling the estimates to calculate the actual treatment effect if the whole population had a colonoscopy. It has the same goal as per protocol— to ask what if everyone complied, but preserved the advantages of randomization. If it varies from the per protocol analysis, we know the IV estimate is closer to the effect size and we know the per protocol analysis has bias.
Ben Recht calculates it here, and explains why it works.
Vinay Prasad MD MPH
Noncompliance is always an issue in randomized control trials for screening. Patients offered a particular screening method may decline the procedure, but there are a variety of reasons why patients might decline. They may not have a family history of disease or may fear the screening procedure itself. Because of such varied reasons, trying to estimate the impact of the screening procedure, rather than the offer of screening, is confounded.
The intention-to-treat analysis counts the rate of bad events in the entire treatment group, and hence measures the effect caused by offering a procedure, rather than the procedure itself. On the upside, intention-to-treat analyses are resistant to the confounding biases associated with the differences between people who choose or decline a particular treatment. The downside, intention-to-treat analyses do not tell us about the benefit of the procedures themselves, rather, they tell us about the benefit of offering the procedures. Hypothetically speaking, if a treatment always works and cures a disease that afflicts 10% of a population, but only 50% of the treatment group accepts the treatment, the relative risk reduction falls from 100% to 50%, dramatically understating the benefit.
There is no perfect way to correct for the misestimates inherent to the intention-to-treat analyses. However, statisticians have developed many proposals to adjust estimates, each with their own set of assumptions. One popular method that makes very few assumptions uses the random assignment to treatment or control as an instrumental variable. Let’s say you want to estimate the effect of some intervention on some outcome, but you didn’t randomize the assignment of the intervention. An instrumental variable is one that affects the intervention but does not affect the outcome. When you have an instrumental variable, there are standard statistical tools to create reasonable estimates of the impact of the treatment on the outcome, even though you didn’t run a randomized experiment.
In the case of screening trials, the offering of the screening affects whether a subject will have the screening procedure. However, we usually suspect that the offering of screening alone has no direct effect on disease. Hence, we can use “was the subject assigned to treatment” as an instrumental variable for estimating the effect of screening on disease.
The absolute risk reduction formula for this instrumental variable is very simple: if we can assume that no one in the control arm has had the experimental procedure, we just take the absolute risk reduction computed in the intention-to-treat analysis and divide it by the compliance rate. In our hypothetical example above, the 50% risk reduction becomes 100%, as it should have. In more realistic examples, we can never be sure that this adjustment perfectly corrects the intention-to-treat analysis, but we can hope it gives us a modestly better estimate.
Let us now use this technique for the NORDICC trial of colonoscopy screening. 28,220 subjects were invited to colonoscopy screening, and 11,843 of those agreed to the screening. There were 56,365 patients in the control group. There were 72 cancer deaths in the treatment arm and 157 in the control arm. The intention-to-treat analysis yields an estimated absolute risk reduction of 0.03%. The instrumental variable method adjusts this number upward: when we divide by the compliance rate, the estimated absolute risk reduction is 0.07%.
Of course, we are not only concerned with the estimated difference in risk, but also in the confidence intervals of the estimate. The simplest technique (called the first order delta method) divides the confidence intervals by the compliance rate. For the NORDICC trial, the absolute risk in an intention-to-treat analysis would have a confidence interval of 0.11% reduction of risk to 0.06% increase of risk. Using the instrumental variable adjustment, the confidence interval ranges from 0.26% reduction to 0.14% increase of risk. A key property of the instrumental variable adjustment is that if the confidence interval crosses 0 (or in other words, the finding is not statistically significant), then the adjusted confidence interval also crosses 0. Another way of saying this is that the instrumental variable adjustment cannot change the z-score.
The authors show this in the supplement
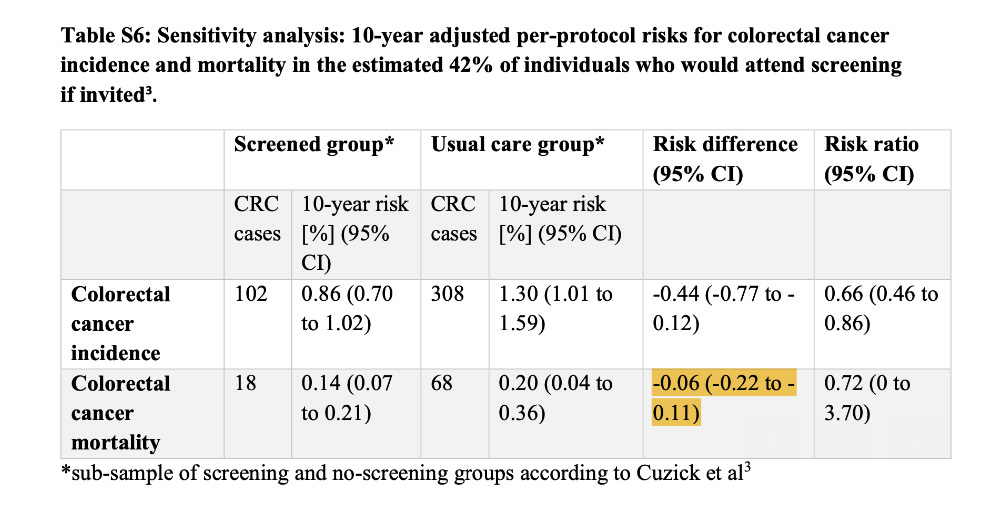
There is no perfect solution to estimating per-protocol effects, but understanding the limitations of the methods we have can give us some further insights into how we think about the results of randomized trials.
 | A guest post by
|
I don't understand authors that present results without confidence interval discussions. For example, authors might gush about their results showing that X had a 0.03 relative risk reduction without mentioning that the results are not statistically significant. If the results are not statistically significant, then why would one say we had a 0.03 relative risk reduction that wasn't statistically significant, rather than there was no statistically significant risk reduction.
While both statements are true, with the first statement there is anchoring around a relative risk reduction, with the second statement there is no anchoring.
What am I missing?
Thanks for the post! I'm not sure that I understand the importance of what you are saying. It appears that in using this technique that you simply scaled the results by the percentage actually treated in the treatment arm. Isn't this the same as just analyzing those that were actually treated?